In association with Keysight Technologies
By Emily Yan
AI is evolving at an unprecedented pace, driving an urgent need for more powerful and efficient data centres. In response, nations and companies are ramping up investments into AI infrastructure.
According to Forbes, AI spending from the Big Tech sector will exceed US$250 billion in 2025, with the bulk going towards infrastructure. By 2029, global investments in AI infrastructure, including data centres, networks, and hardware, will reach US$423 billion.
However, the rapid AI innovations also put unprecedented strain on data centre networks. For instance, Meta’s recent paper on the Llama 3 405B model training cluster shows it requires over 700TB of memory and 16,000 Nvidia H100 graphical processing units (GPUs) during the pre-training phase. Epoch AI estimates that AI models will need 10,000 times more computational power by 2030 than today’s leading models.
The rise of AI clusters
An AI cluster is a large, highly interconnected network of computing resources that handles AI workloads. Unlike traditional computing clusters, AI clusters are optimised for tasks such as AI model training, inference, and real-time analytics. They rely on thousands of GPUs, high-speed interconnects, and low-latency networks to meet the intensive computational and data throughput requirements of AI.
Building AI clusters
An AI cluster is, at its core, functions like a mini network. Building an AI cluster involves connecting the GPUs to form a high-performance computing network where data can flow seamlessly between GPUs. Robust network connectivity is essential, as distributed training relies on the coordination of thousands of GPUs over extended periods.
Key components of AI clusters
AI clusters consist of multiple essential components, as shown in Figure 1.
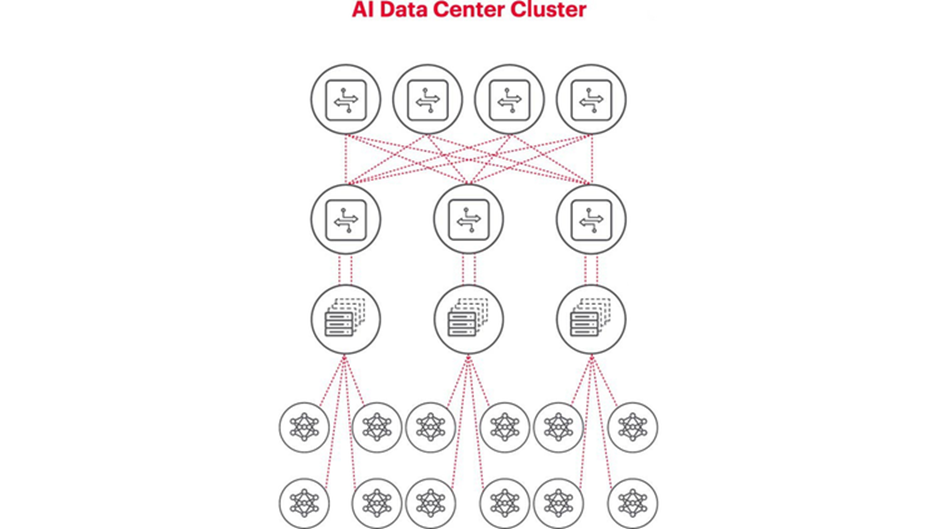
- Compute nodes behave like the brain of the AI clusters, with thousands of GPUs connecting to the top-of-rack switches. As problem complexity increases, so does the need for GPUs.
- High-speed interconnects such as Ethernet enable rapid data transfer between compute nodes.
- Networking infrastructure includes network hardware and protocols supporting data communications between multiple thousands of GPUs over extended periods.
Scaling AI clusters
AI clusters scale to meet the growing AI workloads and complexities. Until recently, network bandwidth, latency, and other factors had limited AI clusters to around 30,000 GPUs. However, xAI’s Colossus supercomputer project shattered this barrier by scaling to over 100,000 Nvidia H100 GPUs – a breakthrough made possible by advancements in networking and memory technologies.
Key scaling challenges
As AI models grow to trillions of parameters, scaling AI clusters involves myriad technical and financial hurdles.
Network challenges
GPUs are effective at performing math calculations in parallel. However, when thousands – or even hundreds of thousands – of GPUs work together on the same task in an AI cluster, if even one GPU lacks the data it needs or encounters delays, every other GPU stalls.
Such prolonged packet latency or packet loss contributed by a congested network can cause packet retransmissions, significantly increasing job completion time (JCT) and leaving millions of dollars’ worth of GPUs sitting idle.
Additionally, AI workloads generate a dramatic rise in east-west traffic (data moving between nodes within the data centre), potentially leading to network congestion and latency issues if the traditional network infrastructure isn’t optimised for these loads.
Interconnect challenges
As AI clusters expand, traditional interconnects may struggle to provide the necessary throughput. To avoid bottlenecks, organisations must upgrade to higher-speed interconnects, such as 800G or even 1.6T solutions.
However, deploying and validating such high-speed links is no easy feat to meet the rigorous requirements of AI workloads. The high-speed serial paths must be carefully tuned and tested for the best signal integrity, lower bit error rates, and reliable long forward error correction (FEC) performance. Any instability in high-speed serial paths can degrade reliability and slow down AI training. Companies need highly accurate and efficient test systems to validate them before deployment.
Financial challenges
The total cost of scaling AI clusters goes well beyond the expense of GPUs. Organisations must factor in power, cooling, networking equipment, and broader data centre infrastructure. However, accelerating AI workloads through better interconnects and optimised network performance can shorten training cycles and free up resources for additional tasks. Each day saved on training can translate into significant cost reductions, making the financial stakes as high as the technical ones.
Validation Challenges
Optimising an AI cluster’s network performance requires testing and benchmarking the performance of both the network fabric and the interconnects between GPUs. However, validating these components and systems is challenging because of the intricate relationships among hardware, architectural design, and dynamic workload characteristics.
There are three common validation issues.
No 1. Lab deployment constraints
The high cost of AI hardware, limited equipment availability, and the need for specialised network engineers make full-scale replication impractical. Additionally, lab environments often have space, power, and thermal constraints that differ from real-world data centre conditions.
No 2. Impact on production system
Testing on a production system reduces can be disruptive, potentially affecting critical AI operations.
No 3. Complex AI workloads
The diverse nature of AI workloads and data sets – varying significantly in size and communication patterns – makes it difficult to reproduce issues and benchmark consistently.
As AI reshapes the data centre landscape, future-proofing network infrastructure is crucial to staying ahead of rapidly evolving technologies and standards. Keysight’s advanced emulation solutions provide a critical advantage by enabling comprehensive validation of network protocols and operational scenarios before deployment.

Emily Yan is product marketing manager at Keysight Technologies. Before joining Keysight, she worked on AI and big data marketing across multiple industries. Yan has an MPA degree from Columbia University and bachelor’s degrees from the University of California, Berkeley, in applied mathematics and economics.






